Using face detection, ROI extraction, and analyzing RGB fluctuations to sense pulse rate remotely
Delving into face detection, ROI extraction, analyzing RGB fluctuations
Jump to section
Loosely interpreted, the word refers to the recording of swellings as shown in the light. In this context, the swellings come from blood being pumped from the heart to every part of the body through a system of blood vessels called the circulatory system.
Every time a person's heart beats, the amount of blood that reaches the capillaries in the fingers and face swells and then recedes. Because blood absorbs light, apps on a phone can measure heart rate by detecting ebb and flow just by using the flash of a camera phone to illuminate the skin and create a reflection.
As a caveat, it shouldn't come as a surprise that DIY heart rate tracking apps don't perform as consistently as nor as well as clinical grade equipment (e.g. electrocardiogram) and known methods (e.g. fingertip pulse oximetry). Studies have found that heart rate readings generated by apps were off by 20+ beats per minute in over 20% of measurements. At the same time, if you're just looking for a high-level overview of your heart rate, it's hard to beat the convenience that this low-cost, non-invasive and safe optical technique provides.
So much goes on underneath the skin that is hard to see with the naked eye. While it's much easier for computers to do the same, they have their own challenges to overcome, too.
Hover over the images below for more info.

It's an optical technique used to detect heartbeat that won't break the piggy bank.

It makes measurements at the surface of the skin to provide valuable information related to the cardiovascular system.

It eliminates the need to surgically implant a device to sense pressure and the risk of infection.

All you need is a common webcam or network IP camera on a smartphone!
Neural networks form the base of deep learning, which is a subfield of machine learning where the algorithms are inspired by the structure of the human brain. That is, neural networks are humankind's attempt to copy the brain to create artificial intelligence. Similar to how the brain works, neural networks take in data, train themseles to recognize patterns in data, and then predict the output for a new set of similar data.
Granted the brain is the most complicated organ in the human body that has been studied and hypothesized for centuries, there's a lot we still don't know. For now, here's what we do know.
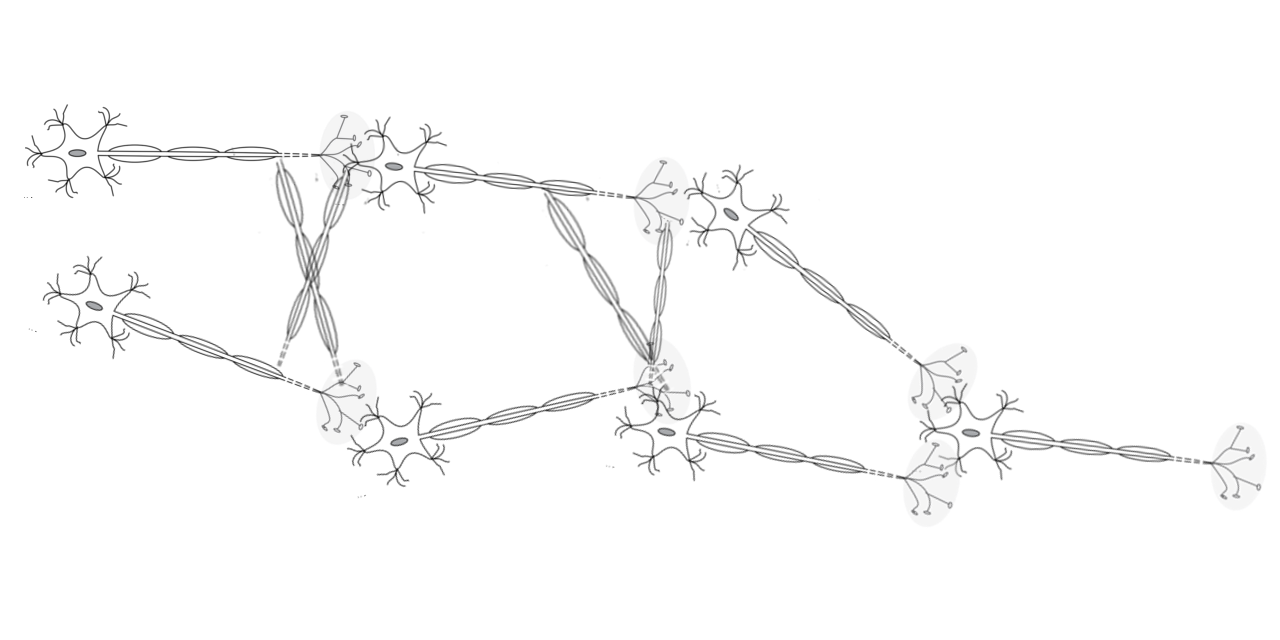
In the human brain, there is a complex network of 85+ billion neurons that interact with each other to communicate and process information based on what we see, hear, move, think, etc. Each neuron has:
Mouse over the below image showing a network of brain neurons to explore what a single neuron looks like in outline form.
Connected to other neurons' axons, dendrites receive neurotransmitters from the axon of other neurons, which in turn creates a small positive spike in the neuron. If the neuron receives enough positive spike, the neuron sends a positive spike down its axon, which then releases neurotransmitters to all neurons connected to its axon branches. This, in turn, produces a positive spike in those neurons — and the cycle goes on and on.
Of note, some connections between neurons are stronger than others, and neurons with stronger connections receive a larger positive spike than neurons with weaker connections. That means neurons with stronger connections are closer to being triggered to release neurotransmitters to their connected neurons.
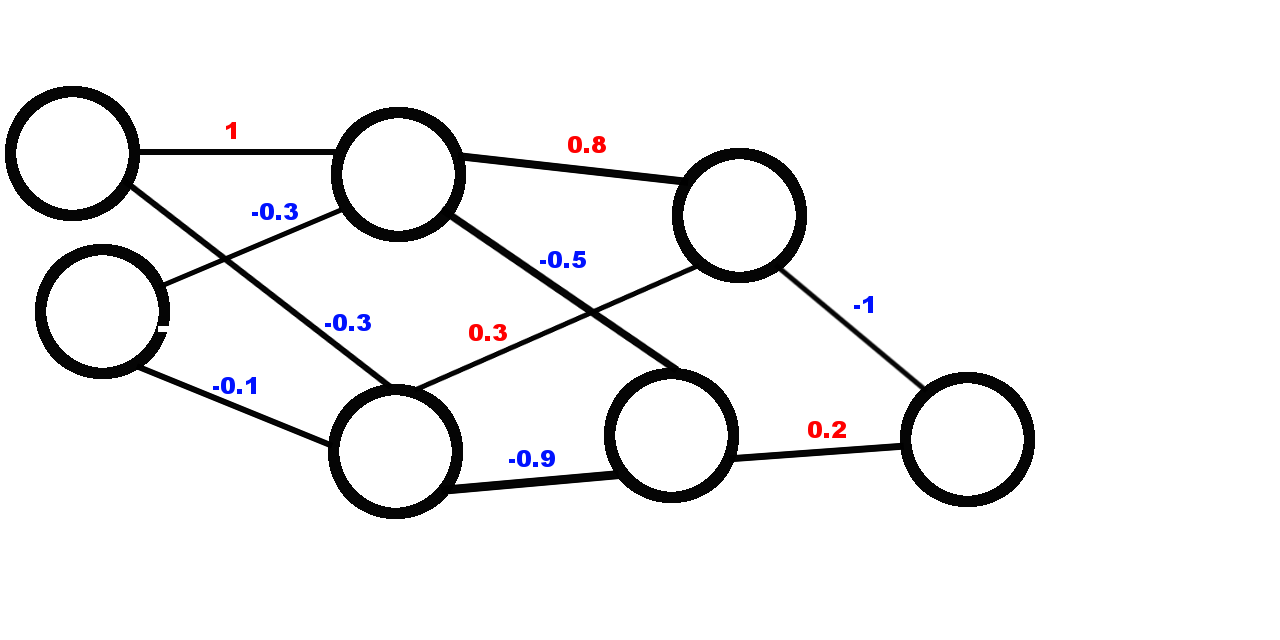
In network graph form, the circles are neurons and the lines are connections between neurons. Each connection has a strength associated with it, called the weight. Weight can range between -1 and 1. Weights in red are positive connections, and weights in blue are negative connections.
A single neuron or node in the graph is called a perceptron. It has many connections to other perceptrons coming in and going out. Inside it, two processes go on. The first sums up all the connections or inputs coming into the perceptron, and the second is known as the activation function. While there are many activation functions available, for our purposes we'll talk about the step function.
The activation function computes how much input the neuron needs before it gets triggered. Let's put it in math terms whereby the function returns 1 if x is positive, and it returns 0 if x is zero or negative. The perceptron then outputs the result of the activation function to each neuron that it is connected to. These outputs are then multipled by the weights associated with each connection. And that's basically a very simplified version of how the brain works and how a neural network functions behind the scenes.
Ultimately, neural networks simulate behavior. Let's start by laying down some key terminology.
A layer is a column of neurons. In our example, we have 4 columns. The first layer is known as the input layer, and the final layer is known as the output layer. There's also something called the bias neuron; it's a neuron like the input neuron, but it's always set to 1. This neuron can be connected to any neuron in the input layer. We'll talk more about this later.
In the context of computer vision, a camera sees a 2x2 image, and pixels can only be black or white. To detect a pattern, we eventually want to see one of two possibilities: either a grid where the upper left quadrant and lower right quadrant are black, or a grid where the lower left quadrant and upper right quadrant are black. Or really, a checkerboard pattern.
In a neural network, each layer is combining features from the previvous layer. Brandon Rohrer helps explain and visualize the above really well in this video.
When an input doesn't end up in a checkerboard pattern, the output neuron should output 0. Of course, neural networks are a lot more complicated than this, so it's not feasible to manually set all the neurons and weights. This is where the genetic algorithm comes in — to learn and evolve ways and algorithms. Those with better behaviors survive and pass on their genes (i.e. the weights), and through evolution the neural network knows how to do the desired task at hand.
Face detection is a way to find and identify human faces in digital images or video. It typically uses a feature invariant method by searching for human eyes, which is one of the easiest features to detect. From there, the algorithm might attempt to detect the mouth, nose, and even the eyes' iris. Once the algorithm concludes that it has found a facial region, it applies additional tests to confirm that it has detected a face.
There are various methods used in face detection, and each has its own advantages and disadvantages:
There are also techniques used in face detection to help identify faces. Removing the background, for example, can help reveal face boundaries for images with a mono-color background. In color images, sometimes skin color can be used to find faces, but it doesn't always work and can do harm. Using motion to find faces by calculating the moving area is yet another technique. The assumption made here is that a face is almost always moving in real-time video. Of course, there's the inherent risk of objects moving in the background.
Nevertheless, detecting faces can be difficult because of varying factors like pose, expression, position and orientation, presence of glasses or facial hair, and even image resolution.
According to Wikipedia, a region of interest (ROI), are samples within a data set identified for a particular purpose. It's a form of annotation, often associated with categorical or quantitative information (e.g. volume), expressed as text or in a structured form.
In the context of computer vision, the ROI defines the borders of an object under consideration. In many applications, symbolic (textual) labels are added to a ROI, to describe its content in a compact way. And within a ROI, there may be individual points of interest (POIs).
There are three fundamentally different means of encoding a ROI:
1.) As an integral part of the sample data set, with a unique or masking value that may or may not be outside the normal range of normally occurring values and which tags individual data cells
2.) As separate, purely graphic information, such as with vector or bitmap (rasterized) drawing elements, potentially with some accompanying plain (unstructured) text in the format of the data itself
3.) As a separate structured semantic information (e.g. coded value types) with a set of spatial and/or temporal coordinates
From the pixels contained in the region of interest, the raw signal can be computed per frame as the mean value of each of the RGB color channels. In doing so, we can average out camera noise contained in single pixels; this is also known as spatial pooling. After normalizing the level of raw signals, we can then compare whether variations are significant.
With the rise in telehealth and more sophisticated machine learning possibilities being discovered, there are so many use cases for this — including but not limited to:
Knowing your heart rate is important because the heart's function is so crucial. Namely, the heart is what's responsible for circulating oxygen and nutrient-rich blood throughout your body. When it's not working as expected, basically everything in the body is affected.
Many top athletes and individuals who regularly exercise are interested in optimizing their training and fitness by understanding how their body responds to training and recovers.
A lower heart rate is one of the positive physiological effects of meditation and can indicate how effect a practice is.
Anxiety disorders are the most common psychiatric disorders today that have been shown to increase the risk of heart disease, so finding a slower heart rate could help with identifying and getting checked out sooner.